
Main Menu
Welcome





It really doesn't need any introduction! Via SciLogs.
...and you should watch it until the end for a surprise.
...and you should watch it until the end for a surprise.
Posted on Thursday 17 January 2013 - 09:44:04 comment: 0
{TAGS}
{TAGS}
A few days ago, I've reported on the sevices of the library at my new institution, the University of Regensburg. Besides already archiving our raw data and getting ready to host Git repositories with our software (both citable by using stable URLs), our library currently publishes four open access journals and offered me to start new ones if I had any plans to do so. Given that there are currently about 9,000 universities on this planet, most if not all of which have their own libraries, we could easily fit all the existing ~32,000 journals in a library-based publishing venture, if all university libraries would just offer the same services our library is offering: 4 open access journals.
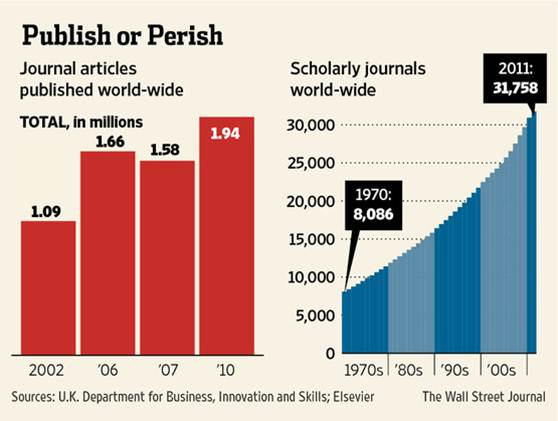
Assuming that most running costs of publishing these almost 2 million articles per year stays constant during the transition, each participating institution faces the opportunity to save up to 40% of their annual subscription budget, or the tax-payer about US$5b annually world-wide, taken together. That's a rare opportunity indeed: provide a huge public service not only without additional costs but actually at great savings. Obviously, this is very different from the projected costs detailed, e.g. in the so-called Finch Report, where huge sums have been suggested to be required for a transition to universal open access. The example of our library shows: a library-based transition to universal open access will not cost a dime - it will save billions. One has to wonder: why didn't the people working on the Finch report get the idea to turn to libraries as the most obvious (and most cost-effective) place to archive the products of scholarly work?
P.S.: The above does of course not imply that I'd believe we'd want to keep roughly 32k different journals, not even for a second. 'Journal' is an outdated format and there are many superior publishing formats available and many more imaginable, but this will be part of a later post. So not that we would, but we could
Assuming that most running costs of publishing these almost 2 million articles per year stays constant during the transition, each participating institution faces the opportunity to save up to 40% of their annual subscription budget, or the tax-payer about US$5b annually world-wide, taken together. That's a rare opportunity indeed: provide a huge public service not only without additional costs but actually at great savings. Obviously, this is very different from the projected costs detailed, e.g. in the so-called Finch Report, where huge sums have been suggested to be required for a transition to universal open access. The example of our library shows: a library-based transition to universal open access will not cost a dime - it will save billions. One has to wonder: why didn't the people working on the Finch report get the idea to turn to libraries as the most obvious (and most cost-effective) place to archive the products of scholarly work?
P.S.: The above does of course not imply that I'd believe we'd want to keep roughly 32k different journals, not even for a second. 'Journal' is an outdated format and there are many superior publishing formats available and many more imaginable, but this will be part of a later post. So not that we would, but we could
Posted on Monday 14 January 2013 - 13:33:30 comment: 0
{TAGS}
{TAGS}
Given the current three infrastructure crises in science, the readily available funds for mitigating these crises currently draining into the pockets of corporate CEOs and their shareholders, and that all the know-how required for such mitigation already is present in libraries, I have repeatedly suggested that libraries are a rational place to sustainably archive and make accessible the three intellectual products of scholarly work today: software, data and publications. Slowly, others are chiming in and even the first peer-reviewed publications appear, suggesting the same solution to these pressing problems.
So you can imagine my excitement, when I learned during a meeting with the head of the library and the responsible technical employee at my new institution in Regensburg, that they already are publishing open access journals! If I wanted to start my own, I could do that right away, they told me. But that was not enough: they also offered me to long-term archive and host our software in a GitHub-like repository and make sure it becomes and remains findable and accessible with a stable URL. They also offered to host Linux repositories of the portion of our software that runs on Linux such that new versions get automatically pushed to all users. On top of all that, they already store data repositories for all the faculty at the university asking for this service, solving all three infrastructure crises from which science is suffering world-wide.
In other words, if all libraries would offer the same services our library here is offering their faculty, universal, sustainable open access to scholarly publications, software and data would already be a reality, with estimated savings (not costs!) of at least around US$5 billion every single year, world-wide. Serials crisis - gone. Data crisis - gone. Software crisis - gone. We'd have the modern scholarly communication system everyone wants but nobody knows how to get there. So, libraries, what are you waiting for? Don't you want to save close to 40% of your subscription budgets?
So you can imagine my excitement, when I learned during a meeting with the head of the library and the responsible technical employee at my new institution in Regensburg, that they already are publishing open access journals! If I wanted to start my own, I could do that right away, they told me. But that was not enough: they also offered me to long-term archive and host our software in a GitHub-like repository and make sure it becomes and remains findable and accessible with a stable URL. They also offered to host Linux repositories of the portion of our software that runs on Linux such that new versions get automatically pushed to all users. On top of all that, they already store data repositories for all the faculty at the university asking for this service, solving all three infrastructure crises from which science is suffering world-wide.
In other words, if all libraries would offer the same services our library here is offering their faculty, universal, sustainable open access to scholarly publications, software and data would already be a reality, with estimated savings (not costs!) of at least around US$5 billion every single year, world-wide. Serials crisis - gone. Data crisis - gone. Software crisis - gone. We'd have the modern scholarly communication system everyone wants but nobody knows how to get there. So, libraries, what are you waiting for? Don't you want to save close to 40% of your subscription budgets?
Posted on Wednesday 09 January 2013 - 15:06:15 comment: 0
{TAGS}
{TAGS}
This is one of a series of interviews the Society for Neuroscience ( SfN) has been putting out on their Youtube channel:
You should have a look at the other 31 videos in the "History of Neuroscience" playlist.
You should have a look at the other 31 videos in the "History of Neuroscience" playlist.
Posted on Tuesday 08 January 2013 - 09:21:12 comment: 0
{TAGS}
{TAGS}
If you trust empirical evidence, science is currently heading for a cliff that makes dropping off the fiscal cliff look like a small step in comparison. As we detail in our review article currently under revision, retractions of scientific articles are increasing at an exponential rate, with the majority of retractions being caused by misconduct and fraud (but also the error-rate is increasing). The evidence suggests that journal rank (the hierarchy among the 31,000 scientific journals) contributes a pernicious incentive: because funds are tight and science is increasingly under pressure to justify its expenditure, people are rewarded for publishing in high-ranking journals. However, there is no empirical evidence that science published in these journals is any different from scientific discoveries published in other journals. If anything, high-ranking journals publish a much larger fraction of the fraudulent work than lower ranking journals and also a larger fraction of the unintentionally erroneous work. In other words, journal rank is like homeopathy, astrology or dowsing: one may have the subjective impression that there is something to it, but any such effects disappear under scientific scrutiny.
As journal rank has only been used as an instructor for the hire-and-fire policy and institutions world-wide for a few decades, the data also project some potentially catastrophic consequences of journal rank: science has been hiring those candidates who are especially good at marketing their science to top journals, but maybe not equally good at the science itself. Conversely, excellent scientists were fired who did not reach institutional requirements for marketing their research. If this is really what has been taking place, it has now been going on just long enough by now to replace an entire generation of scientists with researchers who are particularly good at marketing, providing one potential explanation of why the fraud and retraction rate is exploding just at this particular point in time. However, until a few years ago, this has been a trend that has only been observed by a few bibliometricians.
At the same time, a much more obvious trend has been receiving a lot of attention: the rising costs of acess to the scholarly literature. To counter this trend, three different publishing models have emerged, which only address the access problem, but not the parallel, and potentially underlying problem of journal rank. These models aim to provide unrestricted, open access to publicly funded research results either by charging the authors once for each article (gold), or by mandating them to place a copy not of the final PDF, but of the version approved by the referees (i.e., the version before the publishers format it) in institional repositories (green), or by providing an option for authors to make heir article accessible in a subscription journal by an additional article fee, i.e., if the authors pay the fee, their article becomes openly accessible, if not, it stays behind a paywall (hybrid). Importantly, the three models which are currently aimed at publishing reform are not sustainable in the long term:
As journal rank has only been used as an instructor for the hire-and-fire policy and institutions world-wide for a few decades, the data also project some potentially catastrophic consequences of journal rank: science has been hiring those candidates who are especially good at marketing their science to top journals, but maybe not equally good at the science itself. Conversely, excellent scientists were fired who did not reach institutional requirements for marketing their research. If this is really what has been taking place, it has now been going on just long enough by now to replace an entire generation of scientists with researchers who are particularly good at marketing, providing one potential explanation of why the fraud and retraction rate is exploding just at this particular point in time. However, until a few years ago, this has been a trend that has only been observed by a few bibliometricians.
At the same time, a much more obvious trend has been receiving a lot of attention: the rising costs of acess to the scholarly literature. To counter this trend, three different publishing models have emerged, which only address the access problem, but not the parallel, and potentially underlying problem of journal rank. These models aim to provide unrestricted, open access to publicly funded research results either by charging the authors once for each article (gold), or by mandating them to place a copy not of the final PDF, but of the version approved by the referees (i.e., the version before the publishers format it) in institional repositories (green), or by providing an option for authors to make heir article accessible in a subscription journal by an additional article fee, i.e., if the authors pay the fee, their article becomes openly accessible, if not, it stays behind a paywall (hybrid). Importantly, the three models which are currently aimed at publishing reform are not sustainable in the long term:
- Gold Open Access publishing without abolishment of journal rank (or heavy regulation) will lead to a luxury segment in the market, as evidenced not only of suggested author processing charges nearing 40,000€ (US$~50,000) for the highest-ranking journals, but also by the correlation of existing author processing charges with journal rank. Such a luxury segment would entail that only the most affluent institutions or author would be able to afford publishing their work in high-ranking journals, anathema to the meritocracy science ought to be. Hence, universal, unregulated Gold Open Access is one of the few situations I can imagine that would potentially be even worse than the status quo.
- Green Open Access publishing entails twice the work on the part of the authors and needs to be mandated and enforced to be effective, thus necessitating an additional layer of bureaucracy, on top of the already unsustainable status quo.
- Hybrid Open Access publishing inflates pricing and allows publishers to not only double-dip into the public purse, but to triple-dip. Thus, Hybrid Open Access publishing is probably the most expensive version overall for the public purse.
Posted on Friday 28 December 2012 - 14:19:07 comment: 5
{TAGS}
{TAGS}
When we discovered a novel learning system in the fruitfly Drosophila (Brembs & Plendl, 2008) and then found out how it interacted with the one learning system which is described in all relevant textbooks (Brembs 2009), we weren't quite sure how general these findings would be for other animals and humans. In the subsequent years, genetically similar processes were discovered in the marine snail Aplysia, songbirds and mice, so we started to be quite confident that we had discovered something quite profound. When it turned out that the fly orthologue of the well-known human gene implicated in language, FOXP-2, was also involved in this learning process, we became quite sure that we had something rather evolutionary ancient in our hands. The key to discover this learning process in the diverse species was to exclude learning of environmental stimuli and instead force the subject to learn about thir own behavior - which is why we called this learning process self-learning, as opposed to world-learning, the process that associates environmental stimuli.
For instance, we use the Drosophila flight simulator to train the animals to either attempt right turns or left turns. Whenever we indicate to them, which direction is punished by using different colors, the flies learn about the colors and not about the learning directions, i.e., the world-learning process is activated and no self-learning is involved. If we take the colors away, they learn about their own behavior, i.e., the self-learning process is engaged. Similarly, if mice are allowed to learn the location of a submerged platform in a Morris Water Maze task using the visual cues around the arena, their self-learning process is irrelevant. However, if the lights are switched off then the animals have to learn the location of the platform using self-motion cues, then the same genetic manipulations we use in flies to manipulate self-learning, also affect the learning performance of the mice (Rochefort et al., 2011, see also this researchblogging post for more details).
Now, a new paper from the lab of John Krakauer has been published, which indicates that analogous interactions between self- and world-learning may potentially be taking place in humans as well. As in the other studies, the authors here removed predictive environmental stimuli during training to uncover an additional learning process, which is usually hidden in the background. Because this interaction appears to be strikingly similar to an interaction between learning systems in the fruit fly Drosophila and other animals, the fascinating possibility of an evolutionary ancient arrangement of multiple learning systems is raised.
The authors are able to distinguish two types of learning processes that appear to be engaged simultaneously during certain reaching tasks. In these experiments, the subjects move their hand towards a target, but they are barred from seeing their arms due to a mirror, which hides their arms and displays the contents of a computer screen on which the researchers control the amount of visual feedback the participants get. The basic principle of the training is to compensate for a quick displacement of the target when the participants have already started moving their hand towards it. Participants who are allowed to use visual cues during the learning phase, show a rapid decay back to baseline, if they are tested without the cues after training. If, however, training occurs without visual cues, the decay is attenuated. Thus, similar to the other animals, removing visual cues engages a learning system which is otherwise not triggered, even if the behavior generated during the task is otherwise completely identical.
In flies, we interpreted this finding as the learning of visual cues (world-learning) inhibiting or suppressing the learning of self-motion cues (self-learning), which is also one of the interpretations the authors offer in this new article. In flies, snails, birds and mice, it was shown that self-learning requires different biochemical pathways than world-learning. The authors here refer to world-learning as a model-based learning process and to self-learning as a model-free, reinforcement learning process, which is in agreement with the animal data so far.
However, one finding is difficult to reconcile between the human and the animal experiments: in mice, the self-learning process (also isolated by removing visual cues) is dependent on protein kinase C in the cerebellum (Rochefort et al., 2011), whereas in humans, the model-free (i.e., self-learning) process appears to be cerebellum-independent (cited by the authors of this article).
Taken together, these experiments suggest that learning of behavior and learning of external stimuli are not only handled by evolutionary ancient pathways, spanning the entire bilaterian branch, but that also the rules of their interactions have been conserved over the last 500 million years of evolution.
For instance, we use the Drosophila flight simulator to train the animals to either attempt right turns or left turns. Whenever we indicate to them, which direction is punished by using different colors, the flies learn about the colors and not about the learning directions, i.e., the world-learning process is activated and no self-learning is involved. If we take the colors away, they learn about their own behavior, i.e., the self-learning process is engaged. Similarly, if mice are allowed to learn the location of a submerged platform in a Morris Water Maze task using the visual cues around the arena, their self-learning process is irrelevant. However, if the lights are switched off then the animals have to learn the location of the platform using self-motion cues, then the same genetic manipulations we use in flies to manipulate self-learning, also affect the learning performance of the mice (Rochefort et al., 2011, see also this researchblogging post for more details).
Now, a new paper from the lab of John Krakauer has been published, which indicates that analogous interactions between self- and world-learning may potentially be taking place in humans as well. As in the other studies, the authors here removed predictive environmental stimuli during training to uncover an additional learning process, which is usually hidden in the background. Because this interaction appears to be strikingly similar to an interaction between learning systems in the fruit fly Drosophila and other animals, the fascinating possibility of an evolutionary ancient arrangement of multiple learning systems is raised.
The authors are able to distinguish two types of learning processes that appear to be engaged simultaneously during certain reaching tasks. In these experiments, the subjects move their hand towards a target, but they are barred from seeing their arms due to a mirror, which hides their arms and displays the contents of a computer screen on which the researchers control the amount of visual feedback the participants get. The basic principle of the training is to compensate for a quick displacement of the target when the participants have already started moving their hand towards it. Participants who are allowed to use visual cues during the learning phase, show a rapid decay back to baseline, if they are tested without the cues after training. If, however, training occurs without visual cues, the decay is attenuated. Thus, similar to the other animals, removing visual cues engages a learning system which is otherwise not triggered, even if the behavior generated during the task is otherwise completely identical.
In flies, we interpreted this finding as the learning of visual cues (world-learning) inhibiting or suppressing the learning of self-motion cues (self-learning), which is also one of the interpretations the authors offer in this new article. In flies, snails, birds and mice, it was shown that self-learning requires different biochemical pathways than world-learning. The authors here refer to world-learning as a model-based learning process and to self-learning as a model-free, reinforcement learning process, which is in agreement with the animal data so far.
However, one finding is difficult to reconcile between the human and the animal experiments: in mice, the self-learning process (also isolated by removing visual cues) is dependent on protein kinase C in the cerebellum (Rochefort et al., 2011), whereas in humans, the model-free (i.e., self-learning) process appears to be cerebellum-independent (cited by the authors of this article).
Taken together, these experiments suggest that learning of behavior and learning of external stimuli are not only handled by evolutionary ancient pathways, spanning the entire bilaterian branch, but that also the rules of their interactions have been conserved over the last 500 million years of evolution.
Shmuelof, L., Huang, V., Haith, A., Delnicki, R., Mazzoni, P., & Krakauer, J. (2012). Overcoming Motor "Forgetting" Through Reinforcement Of Learned Actions Journal of Neuroscience, 32 (42), 14617-14621 DOI: 10.1523/JNEUROSCI.2184-12.2012
Posted on Friday 28 December 2012 - 13:40:01 comment: 2
{TAGS}
{TAGS}
Today, I'm attanding a workshop in Cologne organized by and about DataCite. DataCite is an organization that helps make scientific data citable, as the name says (for instance by registering DOIs for data). I was invited there to present the efforts in our lab to establish an infrastructure in which all our data is collected digitally, evaluated and then automatically published in a persistent, citable manner. You can see the slides I used in my presentation on slideshare. The gist was that we feel compelled to implement some of ths technology on our own, even though it occurs to us that they should be offered as a component of the standard scientific infrastructure offered by our institutions. To the end, we use the package Rfigshare for R to publish our data on FigShare at the same time the scientist is evaluating their data, on the fly, seamlessly, without any additional work by the researcher.
The ensuing panel discussion was quite lively and covered many relevant topics such as missing incentives for scientists to share their data, other historical baggage, technical issues such as version control or the differences between different fields of scholarship.
One really exciting new development is a recent linked data collaboration between DataCite and CrossRef. This collaboration provides persitent semantic identifiers, allowing machines to resolve the RDF metadata for any DOI, for example. Another very cool service is the Citation Formatter, go an try it. These developments in content negotiation may seem trivial and these services puny, but the possibilities that these developments offer are quite staggering. A pervasive use of this technology for all scientific literature, data and software would allow us to semantically connect all of science in a machine-readable way. Fantastic!
We now even have data-level metrics. For instance, at stats.datacite.org, they track not only how often a dataset was cited, but also how often the associated DOI was resolved, allowing to indirectly track data usage. On this site you can see, for instance, that in September 2012, the service that we use to deposit our data, FigShare, has generated by far the most successful resolutions (at least that's how I read it).
The ensuing panel discussion was quite lively and covered many relevant topics such as missing incentives for scientists to share their data, other historical baggage, technical issues such as version control or the differences between different fields of scholarship.
One really exciting new development is a recent linked data collaboration between DataCite and CrossRef. This collaboration provides persitent semantic identifiers, allowing machines to resolve the RDF metadata for any DOI, for example. Another very cool service is the Citation Formatter, go an try it. These developments in content negotiation may seem trivial and these services puny, but the possibilities that these developments offer are quite staggering. A pervasive use of this technology for all scientific literature, data and software would allow us to semantically connect all of science in a machine-readable way. Fantastic!
We now even have data-level metrics. For instance, at stats.datacite.org, they track not only how often a dataset was cited, but also how often the associated DOI was resolved, allowing to indirectly track data usage. On this site you can see, for instance, that in September 2012, the service that we use to deposit our data, FigShare, has generated by far the most successful resolutions (at least that's how I read it).
Posted on Wednesday 12 December 2012 - 15:23:48 comment: 0
{TAGS}
{TAGS}
Dr. Douglas Fields penned an article at Huffington Post on open access. There are so many factual errors, false analogies and misleading statements in this article, that I need to highlight just few of the 'wrongest' statements in there (that haven't already been thoroughly debunked by other commenters on the article):
That may be wishful thinking, at least on my part. Last I looked, corporate publishers had been making record profits year over year for the last several decades, with no recession or crisis even making as much as a dent in their profit margins which by now easily exceed 30% and in some cases (I'm looking at you, Wiley) even exceed 40%. Apple would wish they were so lucky...
Now which is it, government or capitalistic control? White or black? Or is 'the government' and 'capitalism' the same shade of grey?
Of course not - the tax-payer has already paid for the research. Why should they pay again? Just to let the corporate publishers make yet higher profits on a product they have contributed little to nothing to?
Of all my 25 or so peer-reviewed articles, only one was ever proof-read and that was a commissioned review article intended for a general audience - and not a research articles. Actually, Elsevier introduced numerous errors into one of my articles...
Too bad there is no empirical evidence supporting the idea that the quality of journals is actually different. This idea of a journal 'rank' is like dowsing, homeopathy or astrology: the people steeped in the system think it's working, but once you apply scientific scrutiny, all effects vaporize.
The mandate covers the article version before the publishers add their value. So if the publishers really do so many important things as the author claims, the mandates are not a threat at all. If, however, the publishers don't really add anything valuable, then why keep paying them?
You say this like this is a bad thing - that's how it should be! I don't want people I don't even know deciding over which papers are relevant to me!
And they're not even doing a good job! I still need to use Google Scholar, PubMed, ISI Web of Science and Scopus to cover all the relevant literature in my field! This is absurd! Just to find my literature, I have to do the exact same search in four different places! It drives me crazy! Can someone please provide a decent tools that covers every single scholarly article? The current way is almost unusable.
Actually, the 'best Journals' with the 'most rigorous review' are the ones who are publishing the vast majority of all such flawed studies. The lower the journal, the more reliable the research, the data shows.
What??? Last I looked, they wanted ALL my copyrights! The author must mean scientific journals on planet Vulcan...
You say this like this isn't the way it already is and has been since science became publicly funded: the taxpayer funds our salaries, we pay the publishers' page charges and our libraries pay the subscription fees. We are validating our own research, publishers are only taking it away from us and store it on their servers so nobody else can get to it - today, scientific research is hardly 'published', when only a small, elite fraction of the 'public' can access it.
That one really takes the cake! Who are the 'subscribers of journals'? We, the scientists and our libraries! Who is paying the university libraries? The public (maybe with the exception of a few private universities in the US)! The public has not only been footing the bills for decades, it has also paid for handsome CEO salaries in the millions and skyrocketing, recession safe shareholder profits to boot. Over 70% of journal subscription revenue stems from public funds...
See above. If the 40% profit margins of Wiley and other corporate publishers are dangerously low, Apple really has a problem.
Now here's something that's not entirely from another planet. We indeed need to take our scholarship back from the corporations. If we wrestle scholarship back into our own control, we can reclaim the US$ 15b or so that our libraries world-wide spend annually on journal subscriptions and free the contained US$ ~6b or thereabouts in corporate profits for innovation and infrastructure (the three big publishers make about 5b annually alone).
scholarly publication as we have known it is dying
That may be wishful thinking, at least on my part. Last I looked, corporate publishers had been making record profits year over year for the last several decades, with no recession or crisis even making as much as a dent in their profit margins which by now easily exceed 30% and in some cases (I'm looking at you, Wiley) even exceed 40%. Apple would wish they were so lucky...
Scientific publication is undergoing a drastic transformation as it passes deeper into government and capitalistic control
Now which is it, government or capitalistic control? White or black? Or is 'the government' and 'capitalism' the same shade of grey?
The idea sounds great, but nothing is free.
Of course not - the tax-payer has already paid for the research. Why should they pay again? Just to let the corporate publishers make yet higher profits on a product they have contributed little to nothing to?
the article was proofread
Of all my 25 or so peer-reviewed articles, only one was ever proof-read and that was a commissioned review article intended for a general audience - and not a research articles. Actually, Elsevier introduced numerous errors into one of my articles...
In this way the quality of the journal was validated by its readers
Too bad there is no empirical evidence supporting the idea that the quality of journals is actually different. This idea of a journal 'rank' is like dowsing, homeopathy or astrology: the people steeped in the system think it's working, but once you apply scientific scrutiny, all effects vaporize.
The government mandate, however, undercuts all the investment involved in validating and publishing the research studies it funds.
The mandate covers the article version before the publishers add their value. So if the publishers really do so many important things as the author claims, the mandates are not a threat at all. If, however, the publishers don't really add anything valuable, then why keep paying them?
Some open-access journals ask reviewers to evaluate only whether the techniques used in the study are valid, rather than judging the significance or novelty of the findings.
You say this like this is a bad thing - that's how it should be! I don't want people I don't even know deciding over which papers are relevant to me!
PubMed, once the authoritative index of biomedical publication, is now apparently competing with Google Scholar.
And they're not even doing a good job! I still need to use Google Scholar, PubMed, ISI Web of Science and Scopus to cover all the relevant literature in my field! This is absurd! Just to find my literature, I have to do the exact same search in four different places! It drives me crazy! Can someone please provide a decent tools that covers every single scholarly article? The current way is almost unusable.
Even with the most rigorous review at the best journals, flawed studies sometimes slip through
Actually, the 'best Journals' with the 'most rigorous review' are the ones who are publishing the vast majority of all such flawed studies. The lower the journal, the more reliable the research, the data shows.
The scientific journals claim no rights to the results of publicly funded scientific research
What??? Last I looked, they wanted ALL my copyrights! The author must mean scientific journals on planet Vulcan...
Do we want a government-run system in which the money for research is supplied by the same body that validates and publishes it?
You say this like this isn't the way it already is and has been since science became publicly funded: the taxpayer funds our salaries, we pay the publishers' page charges and our libraries pay the subscription fees. We are validating our own research, publishers are only taking it away from us and store it on their servers so nobody else can get to it - today, scientific research is hardly 'published', when only a small, elite fraction of the 'public' can access it.
Now the public must foot the bill for what was previously paid by subscribers of journals.
That one really takes the cake! Who are the 'subscribers of journals'? We, the scientists and our libraries! Who is paying the university libraries? The public (maybe with the exception of a few private universities in the US)! The public has not only been footing the bills for decades, it has also paid for handsome CEO salaries in the millions and skyrocketing, recession safe shareholder profits to boot. Over 70% of journal subscription revenue stems from public funds...
The same thing that is happening to newspaper and magazine publishers is happening to science publishers.
See above. If the 40% profit margins of Wiley and other corporate publishers are dangerously low, Apple really has a problem.
One wonders how many new advances in science will never have an opportunity to take root now that scientific publication is an increasingly corporate and government business
Now here's something that's not entirely from another planet. We indeed need to take our scholarship back from the corporations. If we wrestle scholarship back into our own control, we can reclaim the US$ 15b or so that our libraries world-wide spend annually on journal subscriptions and free the contained US$ ~6b or thereabouts in corporate profits for innovation and infrastructure (the three big publishers make about 5b annually alone).
Posted on Wednesday 21 November 2012 - 17:16:18 comment: 0
{TAGS}
{TAGS}
Back in April, just as I set out on my crazy teaching assignment in Leipzig, I received a manuscript on academic publishing which was accepted for publication, entitled "The Poverty of Journal Publishing". Back then, I didn't have the time to read it, but I have now. I think, you should read it too. It's a thorough dissection of the current crisis in academic publishing with four possible solutions, according to the authors:
Now more and more people are realizing that the status quo is a dead end and people are more and more coming up with the rational solution: we need to rid ourselves of parasitic publishing corporations. Academic publishing is bound to go the way of the music industry, it's just a matter of us pushing strong enough
- the further development of open access repositories
- a fair trade model of publishing regulation
- a renaissance of the university presses
- move away from private, for-profit publishing companies toward autonomous journal publishing by editorial boards and academic associations
Now more and more people are realizing that the status quo is a dead end and people are more and more coming up with the rational solution: we need to rid ourselves of parasitic publishing corporations. Academic publishing is bound to go the way of the music industry, it's just a matter of us pushing strong enough
Posted on Monday 19 November 2012 - 16:19:26 comment: 0
{TAGS}
{TAGS}
If you happen to come across this obscure blog, you're likely to already know that physicists communicate their scientific findings via a non-peer-reviewed pre-print database called arXiv. However, they still 'publish' these preprints in traditional academic specialty journals for the 'prestige'. Many on the non-physics side of the scientific community envy physicists for more than just not being the science  : they'd like to also be able to communicate quickly and get prestige later. After all, it's a step forward from mingling the two. Paleontologists feel that way, chemists and apparently biologists also. For a while, there even was a dedicated non-physics preprint archive operated by Nature Publishing Group, Nature Precedings, for just that purpose.
: they'd like to also be able to communicate quickly and get prestige later. After all, it's a step forward from mingling the two. Paleontologists feel that way, chemists and apparently biologists also. For a while, there even was a dedicated non-physics preprint archive operated by Nature Publishing Group, Nature Precedings, for just that purpose.
Isn't there anybody around who thinks this solution to the problem is completely bizarre? Why would anyone in their right mind publish something first, then publish it again at some undeterminable later time, when everybody already knows about it, only so that you afterwards have two different versions of the same work in two different places and the authors can display something on their CVs?
Isn't the following scenario much more rational?
Once you have your manuscript ready, you publish it in a world-wide, peer-reviewed database of primary research results, together with your data and your software. Those in your community will see your paper by virtue of keywords or social features in the database. If you think your paper has implications beyond your immediate field, you can amend it with a short, general summary that's being posted to a news feed where all such marked papers can be read by professional 'selectors' who do nothing all day but screen such submissions for 'the best' science (you already see where this is going, aren't you? ). Maybe the companies employing these 'selectors' could be called "Science" or "Nature" or some such. These companies can then provide lists of 'hot' research to their subscribers and of course any 'selected' research will bring eminent prestige to the authors, especially if more than one such company selected it. There are a lot of advantages to publishing scholarly work this way, not the least of which is that each company can build a track record as to how often non-selected science turned out to be ground-breaking advances of general relevance and how often selected work had to be retracted. There would be actual competition between these services for subscribers and the services would have to show that they can predict what will be relevant and important science better than their competitors in real and scientifically testable numbers.
). Maybe the companies employing these 'selectors' could be called "Science" or "Nature" or some such. These companies can then provide lists of 'hot' research to their subscribers and of course any 'selected' research will bring eminent prestige to the authors, especially if more than one such company selected it. There are a lot of advantages to publishing scholarly work this way, not the least of which is that each company can build a track record as to how often non-selected science turned out to be ground-breaking advances of general relevance and how often selected work had to be retracted. There would be actual competition between these services for subscribers and the services would have to show that they can predict what will be relevant and important science better than their competitors in real and scientifically testable numbers.
Now why don't we just switch to a system like this, I wonder?
: they'd like to also be able to communicate quickly and get prestige later. After all, it's a step forward from mingling the two. Paleontologists feel that way, chemists and apparently biologists also. For a while, there even was a dedicated non-physics preprint archive operated by Nature Publishing Group, Nature Precedings, for just that purpose.Isn't there anybody around who thinks this solution to the problem is completely bizarre? Why would anyone in their right mind publish something first, then publish it again at some undeterminable later time, when everybody already knows about it, only so that you afterwards have two different versions of the same work in two different places and the authors can display something on their CVs?
Isn't the following scenario much more rational?
Once you have your manuscript ready, you publish it in a world-wide, peer-reviewed database of primary research results, together with your data and your software. Those in your community will see your paper by virtue of keywords or social features in the database. If you think your paper has implications beyond your immediate field, you can amend it with a short, general summary that's being posted to a news feed where all such marked papers can be read by professional 'selectors' who do nothing all day but screen such submissions for 'the best' science (you already see where this is going, aren't you?
). Maybe the companies employing these 'selectors' could be called "Science" or "Nature" or some such. These companies can then provide lists of 'hot' research to their subscribers and of course any 'selected' research will bring eminent prestige to the authors, especially if more than one such company selected it. There are a lot of advantages to publishing scholarly work this way, not the least of which is that each company can build a track record as to how often non-selected science turned out to be ground-breaking advances of general relevance and how often selected work had to be retracted. There would be actual competition between these services for subscribers and the services would have to show that they can predict what will be relevant and important science better than their competitors in real and scientifically testable numbers.Now why don't we just switch to a system like this, I wonder?
Posted on Friday 16 November 2012 - 16:20:08 comment: 0
{TAGS}
{TAGS}
Render time: 0.2614 sec, 0.0091 of that for queries.