
Main Menu
Welcome





One would think that in today's information age, scientists can easily keep up with new discoveries. However, these discoveries are buried in 24,000 journals most of which cannot be accessed by the individual scientist, because his/her institution does not subscribe to them. Thus, in order to keep current, here's what I have to do:
- Pick ten, fifteen or so journals I have access to and which have a reasonable chance of publishing something important in my field and read their tables of contents religiously
- Go through stored PubMed keyword searches (even though PubMed is ~4 weeks behind publication date)
- Read F1000 alerts
- Subscribe to 3-4 mailinglists on which some helpful person posts press-releases in close enough fields
- Screen citeUlike recommendations and FriendFeed subscriptions for interesting papers
- Subscribe to science news wires
- Listen to science podcasts
I'd guesstimate that this takes about 12-14h per week just to keep on top of things. Much of this time is spent looking for relevant information, not actually taking much information in. Reading the actual papers comes on top of that. In other words, I could easily save around 5-10 hours of my work-week (spent doing an extremely boring task!), if there existed a service which would bring me relevant scientific information such that I could minimize my search time and maximize read time. Alas, such a service doesn't exist. One of the prime reasons why it doesn't exist is that the information is so distributed and hard to access, making standardized searches impossible. What would be required, is a single entry-point scientific database where one could easily implement such a service. Given the history and the financial interests of a ~4 billion-dollar market cornered by 3-4 private corporations, the only thing on the horizon which currently looks like it could shake up the scholarly publishing landscape enough to even dream of getting a modern information service for scientists implemented is PLoS One. Which is one of the reasons I support PLoS One by donating time as Academic Editor handling the peer-review of submitted manuscripts (besides also acting as a reviewer for them).
The post by Kent Anderson at Scholarly Kitchen mentioned above shows just how much opposition my dream faces. Interestingly, from their 'about' page, it appears to me that Kent never worked as a scientist, he isn't even trained in science, he's an English major. Nevertheless, Kent pretends he knows how to distinguish between different scientific manuscripts. He clearly thinks that some of my colleagues' work is 'noise', 'chaff' or 'pollution', while other work is not:
So, yes, I am anti-noise and pro-signal, anti-chaff and pro-wheat, anti-pollution and pro-filtration.
Noise, chaff, and pollution in science should be controlled upstream by scholarly publishers.
Kent has got to be kidding us! Just who does he think commissioned this task to publishers? I sure didn't!Noise, chaff, and pollution in science should be controlled upstream by scholarly publishers.
Only someone with zero scientific training and experience would ever say this with reference to journal selectivity! To paraphrase the sort of filtering he describes: some ex- (or non-)scientist choosing according to his/her own whim what he/she thinks deserves to be spoon-fed to scientists. On what planet does this actually work? Definitely not on the one where I live. Some examples from the area I know best, my own field:
In my personal rank of my own 15 peer-reviewed experimental papers, this one in PLoS One ranks substantially higher than this one in Science. Obviously, my ranking of my own work is different from how other people see it. That’s definitely not what I want from my filter. That’s like asking a stranger to pick for me from the menu even though I already know what I would like to eat. Or like me, with English as third language, lecturing Kent on the use of adverbs in the works of Shakespear. Or Kent telling me how I should get my science.
Thus, the people Kent thinks we should commission for the filtering or selecting, can’t even do this the way I want for my own stuff! Why would I outsource such an important task to someone obviously not capable of accomplishing the task the way I need it?
But it gets worse. Because the sorting algorithm of professional editors doesn’t necessarily always correspond to that of professional scientists, stuff gets on my desk I rather wouldn’t want to see. According to my experience and judgment, in my field of Drosophila behavioral Neurogenetics, this Nature paper is arguably among the worst I’ve come across in the last few years. What kind of filter lets this sort of ‘pollution’ through? ‘Pollution’, by the way, is a sort of word I'd never use on any of my colleagues’ work, no matter how bad I personally may think it is (because I know I may be dead wrong).
Anyway, with gaping holes big enough for airplanes, that’s not much of a filter, is it?
But Kent goes yet further and pulls out this gem:
If being published in a journal no longer immediately carries the imprimatur of having cleared a high bar of scrutiny, then the form itself is at risk. Journals could become merely directories of research reports. And publishers who are truly setting standards should take notice of the risk the drift toward directories poses.
ROFLMAO! Only someone who has never worked as a scientist could make such a naive statement. It’s about as close to reality as claiming that ridiculously high salaries keep politicians from taking bribes.The filter-function Kent is talking about is non-existent. I personally know two colleagues (one male one female) who regularly take ‘filter-units’ (read professional editors) out to expensive dinners to explain to them why their work should pass through the filter. Add to that the fact that this filter of professional editors proudly proclaims they don’t even care when professional scientists suggest papers which should get filtered, e.g.:
there were several occasions last year when all the referees were underwhelmed by a paper, yet we published it on the basis of our own estimation of its worth.
Research repositories, or directories if you will, are the future of scientific publishing, combined with a clever filtering, sorting and evaluation system that of course still includes human judgment, but doesn’t exclusively rely on it, and definitely not for the publication process itself (see below).Pre-publication filtering is a fossil from Henry Oldenburg’s time and its adherents would do good to have a look at the calendar (and I don’t mean the weekday, lol). I guess it’s an ironic coincidence that my comment on a Nature opinion article on how flawed journal rank is for evaluating science was published in Nature this very same week. That article, by the way, makes some very interesting and valid points and the lively discussion in the comments-section shows just how close this topic is to every scientist's heart.
Traditional reader-pays journals derive their revenues from the trust their readers place in them.
One really has to wonder where Kent gets all these naive ideas from? There isn’t a single library on this planet that covers all the journals where I have ever wanted/needed to read a paper in. Our library isn’t even close to covering my needs (but has plenty of subscriptions of no use at all to me). Publishers shove journal packages down libraries’ throats, to make sure that any such effect, if it even ever existed, doesn’t hurt their bottom line. What would work, though, is to have a subscription service in the future that relies on the expertise and judgment of today’s journal editors for some portion of my post-publication filtering and then, for some subscription fee, I get to chose which ones come closest to my needs. True competition for the best editors serving the scientific community!Clearly, there’s a lot of money on the table, and PLoSONE is getting that money by publishing 5,400+ articles per year.
I can’t believe Kent just seriously mentioned money without quoting the record 700m dollar adjusted profit of Elsevier in 2008 alone (I seem to recall the rest of the economy tanked that year) and how they and the other corporate publishers make their money: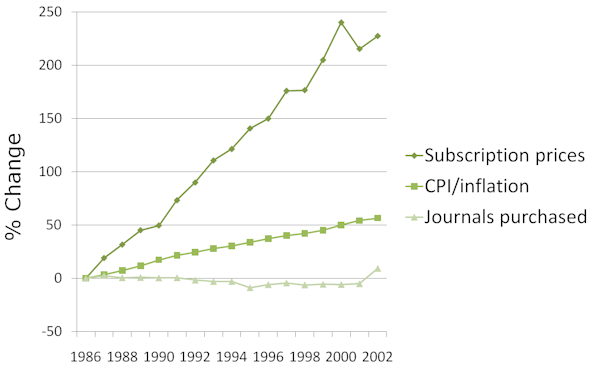
I find it highly suspicious if someone talks about a few thousand dollars for a non-profit organization, without mentioning private multinational corporations making record profits in the billions every year in taxpayer money off of the status quo.
There seems to be a conflict of interest with author-pays at the journal level, at the business model level.
Which, I would tend to hope, is precisely why PLoS is not a corporate, for-profit publisher like almost everybody else in the business. Editors at a reader-focused journal would have very likely forced the authors of these papers to confront some of the problems ArsTechnica and ScienceBlogs found with them, or the paper would have been rejected as part of the 80-95% of papers rejected by these journals.
Why? Because professional editors are somehow god or at least better than professional scientists at predicting the future? Does every journal editor now have an astrologist at his/her disposal? I guess whichever deity Kent envisages as being capable of that task, he/she/it missed the paper I linked to above, eh? What reason is there to believe that professional editors should be any better than Einstein in evaluating science? Einstein famously opposed Quantum Mechanics all his life. Is Kent seriously trying to tell us that a bunch of editors and publishers know their areas of science better than Einstein did his physics? I don’t know what scholarly publishing system Kent is describing in his post, but if it ever existed on this planet, it was a dinosaur long before I got into it 15 years ago.We, the scientists, are producing more valid, important, potentially revolutionary results than anyone could ever read, sort, filter or comment on. Nobody knows if one day our society will depend on a discovery now opposed by the Einsteins of today. Then, it will be a boon to have a single entrypoint to the open access scientific literature (yes, hopefully a directory!!) and send text- and data-mining robots to find the results on which to build the next generation of scientific explanations. Because we produce more (and more important) discoveries than ever before, the old system of pre-publication filtering is the most epic failure among many in our current scholarly publishing system. Granted, we are still in the process of building a better, more suited one. But you’re not helping by putting your head in the sand and pretend everything is a-ok. So I urge everyone to get with the program and support publishing reform with the scientists and the taxpaying public in mind instead of defending corporate publishing profits!
There is not a single rational reason for having 2 places where scientific research is published, let alone 24,000.
It also struck me as odd that Kent made creating a brand name sound like a bad thing:
Then, very quickly, PLoS underwhelmed — it went old school, publishing a good traditional journal initially and then worrying about traditional publisher concerns like marketing, impact factor, author relations, and, of course, the bottom line. PLoS fell so quickly into the traditional journal traps, from getting a provisional impact factor in order to attract better papers to shipping free print copies during its introductory period to dealing with staff turmoil, it soon looked less radical than many traditional publishers did at the time.
It is the very system Kent defends in his post which forces anybody trying to modernize a fossilized organization to start by creating a brand name with the help of a little artificial scarcity. It worked for potatoes in France and it worked for high-ranking journals such as Nature, Science or PLoS Biology. Once brand and reputation were established using the old system, only then was it possible to start a new, truly transformative publishing model. This was a very clever strategy! What else could PLoS have done and succeed? It was the only way how anyone would try to get a foothold in a 400 year-old market, dominated by three or four billion-dollar private corporations.It needs to be emphasized that the above is not in any way intended to belittle, bad-mouth or denigrate professional journal editors. In my own personal experience, they are very bright, dedicated, knowledgeable, hard-working science-enthusiasts. I have the impression that they are passionate about science and believe in their ability to sort the ‘wheat from the chaff’. It’s just that the task that Kent seems to intend for them is not humanly possible to carry out any longer. The current system has become woefully inadequate and has professional scientists and professional editors needlessly pitted against each other, rather than having them work together for the advancement of science. In our ancient science communication system, bogged down by historical baggage, animosities between the two camps are inevitable, but highly counterproductive. Most people have realized this by now, which is only one of the reasons why PLoS One is such a striking success.
What kind of service do I have in mind to replace the current, inadequate system? If I were king for a day and were allowed to decide how scholarly publishing should work, here’s what I’d want to have: Four different sets of filters. One for new publications, one for my literature searches, one for evaluations and one for serendipitous discovery of interesting research.
1. New publications (within the current week).
This is a layered set of filters. The first layer is unfiltered: I must read every single paper that is published in the field(s) I define by keywords and tags. This is my immediate field and I cannot afford to miss anything in it, no matter what. In my case, these fields could be Drosophila behavioral neurogenetics and operant learning in any model system, both further constrained by some additional tags/keywords. The second layer would include all invertebrate neuroscience, but only those who have been highlighted/bookmarked by colleagues (or editors, or bloggers, etc.) in my own field. This layer would include social filter technology such as implemented in FriendFeed, Mendeley, citeUlike, etc (which I all use). The third layer would include all of neuroscience. There, I would have a relatively high threshold with many of my selected colleagues/editors/bloggers (in neuroscience) having to tag/flag it before I get to see it and it would include some form of discovery/suggestion tool such as the one in citeUlike. For all of Biology, I would only like to see reviews or press-releases of reports that have been marked as groundbreaking by colleagues/editors (in biology). For the rest of science, I wouldn’t understand neither papers nor reviews so only press-releases or popular science articles would be what I’d like to see, maybe 2-3 per week.
This 5-layered filter set would automatically deliver a ranked list of brand-new scientific publications to my desk every week, a one-stop shop for science news, no additional searching required. Icing on the cake would be a learning algorithm that remembers how I re-ordered the items to improve the ranking and filtering next week. This service would be flexible and tuneable such that every single scientist gets their own, customized, tailored-to-fit science news service.
2. Literature searches
There, I’d like to have a single front-end, not three, as it is now (PubMed, WoK and Google Scholar). In the search mask, I can define which words should appear where in the full-text of the article. If my searches turn up too many results, I want the option to sort by any or all of at least these criteria: date of publication, citations, bookmarks, reviews, media attention, downloads, comments.
3. Evaluations
Today, whenever people or grants need to be evaluated for whatever reason, in most cases it is physically impossible to read even only the most relevant literature, that’s the cost of our growth. So in order to supplement human judgment, scientifically sophisticated metrics should be used to pre-screen whatever it is that needs to be evaluated according to the needs of the evaluator. Multiple metrics are needed and I’m not talking single digits. The metrics include all the filter systems I’ve enumerated above, obviously.
4. Serendipity
I want to set a filter for anything scientific that is being talked about in the scientific community, no matter the field. If it generates a certain (empirically determined) threshold, I want to know about it (think FriendFeed technology).
The above system of filters and ranks would be possible with the available technology today. It would encompas the best integration of human and machine-based filtering system we can currently come up with and it would easily be capable to do a much better job than today’s actual system, even if it may not be perfect initially. I would never see anything that is irrelevant to me and if the system isn’t quite where I want it to be yet, it’s flexible enough to tweak it until it works to my satisfaction. What is required for it: something like ORCID, a reputation system and a full-text, open-access scientific literature standard, none of which poses any technical challenge.
Thus, the only thing between me and the system described above is the status quo. Along comes Kent Anderson, who definitely doesn't have to stay on top of scientific developments, probably never published a single peer-reviewed scientific article in his life and maybe never even read one. On top of that, his comments to our criticisms blatantly show that he doesn't have the slightest idea what I'm talking about when I mention the layered filter and rank system I described above:
It’s not an either-or situation. I think systems that allow community filtering or individual filtering are fine. But I think those systems are overburdened and not helped by having a loose filter upstream from “journals” like PLoSONE and others.
What??? It’s not an either-or situation? Of course it is! There isn’t a standard with which one could get access to the full text of all the literature! That should be obvious to anybody with the slightest familiarity of how these filters work.What??? Kent is worried the modern information technologies I cited above may be ‘overburdened’ with papers? That’s like saying the 1000hp tractor may be overburdened by the weight a single horse could pull!
Kent apparently seems to think that his horse and our tractor would go well hand in hand. I tend to think it would look more like this if we combined his traditional with a modern publishing system:

Kent Anderson, of all people, has the gall to come and try to tell scientists how they should organize their workflow by telling us that we shouldn't abandon this petrified, decrepit, ghastly plague of a publishing system, because ignoramuses like him know better what's good for science! To this I can only sing along with Jon Stewart and his Gospel choir!

UPDATE: Cameron Neylon has also weighed in on the issue.
Posted on Thursday 29 April 2010 - 16:41:03 comment: 0
{TAGS}
{TAGS}
You must be logged in to make comments on this site - please log in, or if you are not registered click here to signup
Render time: 0.2231 sec, 0.0290 of that for queries.